Test-Time Prompt Tuning for Zero-shot Generalization in Vision-Language Models
Manli Shu1, Weili Nie2, De-An Huang2, Zhiding Yu2,
Tom Goldstein1, Anima Anandkumar2,3, Chaowei Xiao2,4
1 University of Maryland, 2 NVIDIA, 3 Caltech, 4 Arizona State University
paper code
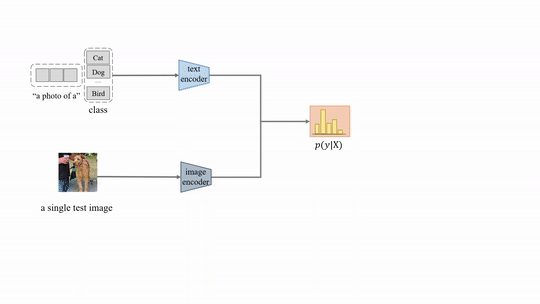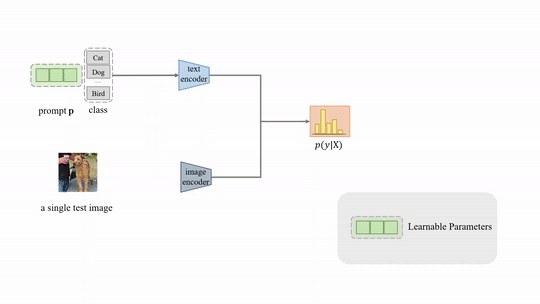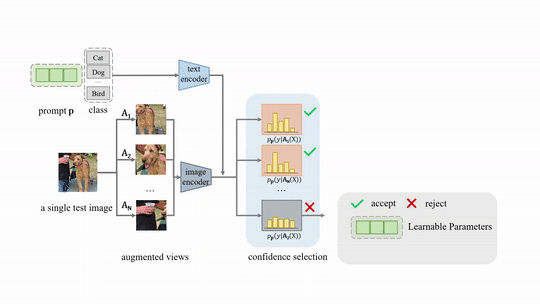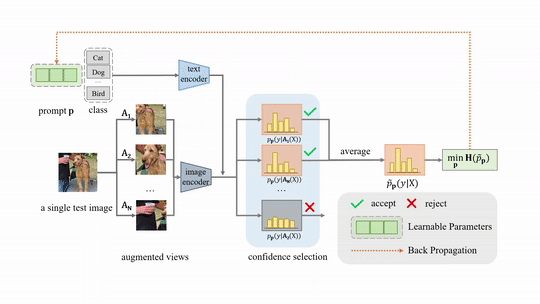
Test-time Prompt Tuning (TPT) for image classification.
Abstract: Pre-trained vision-language models (e.g., CLIP) have shown impressive zero-shot
generalization in various downstream tasks with properly designed text prompts. Instead of relying on hand-engineered prompts, recent works learn prompts using training data from downstream tasks, but this can be expensive and hard to generalize to new tasks and distributions. To this end, we propose test-time prompt tuning (TPT) as the first prompt tuning method that can learn adaptive prompts on the fly with a single test sample. TPT optimizes the prompt by minimizing the entropy with confidence selection so that the model has consistent predictions across different augmented views of each test sample. In the setting of evaluating natural distribution shifts, TPT improves the zero-shot top-1 accuracy of CLIP by 3.6% on average, even surpassing previous prompt tuning approaches that additionally require task-specific training data. In the setting of evaluating across-dataset generalization with unseen categories, TPT performs on par with the state-of-the-art approach that uses training data.
Test-time Prompt Tuning
TPT tunes adaptive prompts on the fly with a single test sample. The tuned prompt is adapted to each task on each specific test sample. TPT retains the zero-shot generalization setting since no additional training data or annotations are used.
We explore TPT on two downstream tasks: image classification and context-dependent visual reasoning. For each downstream task, we design a customized test-time tuning strategy that fits the nature of the task.
For the downstream task of image classification, TPT optimizes the prompt to encourage consistent predictions across augmented views of the same test image by minimizing the marginal entropy. In addition, we introduce confidence selection to filter out noisy augmentations.

Test-time Prompt Tuning (TPT) for image classification.
For context-dependent visual reasoning on Bongard-HOI benchmark, a test sample contains two sets of support images (i.e., context) and a query image for evaluation. On this task, TPT tunes both the prompt and class tokens to learn the context and differentiate between the two support sets.

Test-time Prompt Tuning (TPT) for context-dependent visual reasoning (Bongard-HOI).
We summarize existing prompt tuning methods for CLIP, and compare the differences between TPT and existing methods.
| Prompt Type | Learnable | No training data | Input-adaptive |
|---|---|---|---|
| Hand-crafted | ✓ | ||
| CoOp | ✓ | ||
| CoCoOp | ✓ | ✓ | |
| TPT (ours) | ✓ | ✓ | ✓ |
Evaluation
Below are the main results from our paper. To learn more about the datasets and baselines, we refer readers to Section 4 of our paper.
Generalization to Natural Distribution Shifts
Compared to existing prompt tuning methods that requires training data, TPT generalizes better to data distribution shifts. Note that among the methods in the table below, CoOp and CoCoOp are tuned on ImageNet using 16-shot training data per category. Baseline CLIP, prompt ensemble and TPT (ours) do not require training data.
| Method | ImageNet(IN) | IN-A | IN-V2 | IN-R | IN-Sketch | Average | OOD Average |
|---|---|---|---|---|---|---|---|
| CLIP-RN50 | 58.16 | 21.83 | 51.41 | 56.15 | 33.37 | 44.18 | 40.69 |
| Ensembled prompt | 59.81 | 23.24 | 52.91 | 60.72 | 35.48 | 46.43 | 43.09 |
| CoOp | 63.33 | 23.06 | 55.40 | 56.60 | 34.67 | 46.61 | 42.43 |
| CoCoOp | 62.81 | 23.32 | 55.72 | 57.74 | 34.48 | 46.81 | 42.82 |
| TPT (ours) | 60.74 | 26.67 | 54.7 | 59.11 | 35.09 | 47.26 | 43.89 |
| TPT + CoOp | 64.73 | 30.32 | 57.83 | 58.99 | 35.86 | 49.55 | 45.75 |
| TPT + CoCoOp | 62.93 | 27.40 | 56.60 | 59.88 | 35.43 | 48.45 | 44.83 |
Cross-Datasets Generalization
In each matrix $A$, $A_{i, j}$ is the normalized relative improvement on the $j_{th}$ dataset of using the prompt tuned on the $i$-th dataset. The value $A_{i, j}$ stands for how well a method trained on a source dataset $i$ performs on a target dataset $j$, in comparison with a zero-shot CLIP baseline (using a hand-crafted prompt). Thus, the higher, the better. The last row is the performance of TPT, which is not tuned on any source dataset. The last column summarizes the average improvement over 10 datasets, measuring the overall generalization ability across the 10 datasets.

Cross-dataset improvement normalized by the zero-shot baseline performance.
Context-dependent Visual Reasoning on Bongard-HOI
we follow the setup in Jiang et al, and compare TPT with previous methods on 4 test splits of Bongard-HOI respectively. In Bongard-HOI, test images are split into four sets by their overlap in the HOI concept with the training data: whether the action $a$ or the object $o$ has appeared in the training data. Note that our CLIP-based TPT is not trained on the training split of Bongard-HOI, and thus the definition of the four splits is not strictly applicable to TPT.
| Method | Test Splits | Average | |||
|---|---|---|---|---|---|
| seen act., seen obj. | unseen act., seen obj. | seen act., unseen obj. | unseen act., unseen obj. | ||
| CNN-baseline | 50.03 | 49.89 | 49.77 | 50.01 | 49.92 |
| Meta-baseline | 58.82 | 58.75 | 58.56 | 57.04 | 58.30 |
| HOITrans | 59.50 | 64.38 | 63.10 | 62.87 | 62.46 |
| TPT (w/ CLIP-RN50) | 66.39 | 68.50 | 65.98 | 65.48 | 66.59 |
In the table above, CNN and Meta baselines are implemented based on a ResNet-50 (RN50). “*” denotes that the method uses ground truth HOI bounding boxes to assist the inference.
Citation
If you find our work useful, please consider citing:
@inproceedings{shu2022tpt,
author = {Manli, Shu and Weili, Nie and De-An, Huang and Zhiding, Yu and Tom, Goldstein and Anima, Anandkumar and Chaowei, Xiao},
title = {Test-Time Prompt Tuning for Zero-shot Generalization in Vision-Language Models},
booktitle = {NeurIPS},
year = {2022},
}
Contact
For any questions, please contact Manli Shu (manlis@cs.umd.edu).